WinActor Ver.6.3.0から登場した「WinActorEye」のOCR機能(画像データのテキスト部分を、文字データに変換する機能のこと)があることご存知の方も、ご存じでなかった方も必見です!
実際に使ってみるとすごく便利なんです。
もしかしたら本格的なOCRツールまで導入しなくても良くなっちゃうかもしれません!?
実際にPDFをOCRで読んでみました!結果
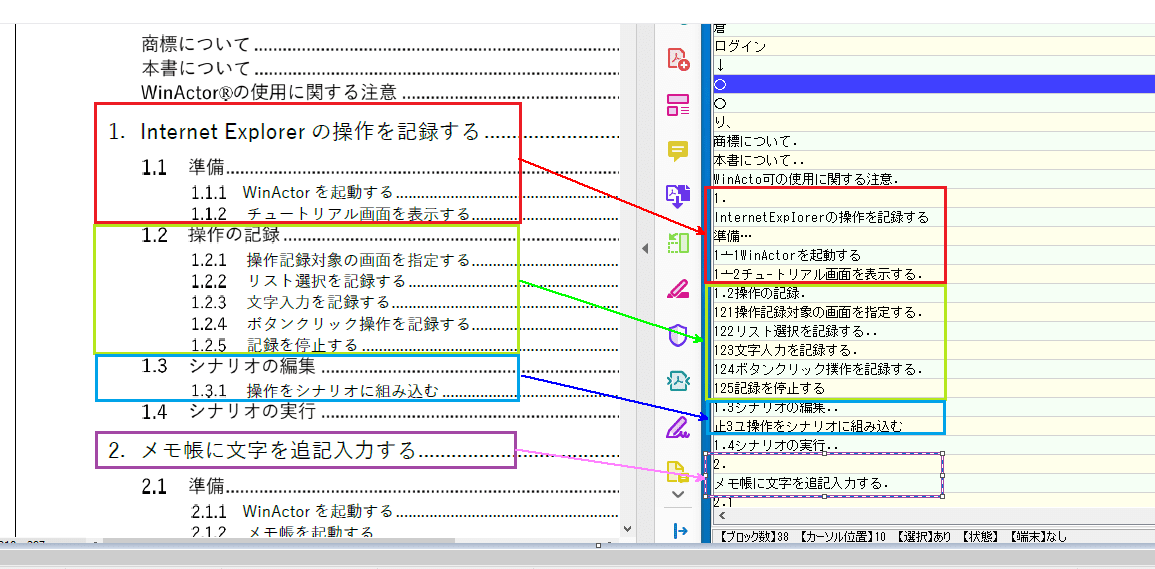
ふむふむ、すべて綺麗にとはいかないですが、意外と日本語がちゃんと読めてます!
ただし、この精度をすべてのデータで保つことはできなそうです。
今回も比較的ちゃんと読めた画像をアップしてます(;’∀’)
でも、例えばこれが基幹システムツールの表内にある取得したい数値でグレーアウトしてて、マウスカーソルで値がとれない!!であったりすると、、
結局最終チェックの突合作業は人の目で確認するしかなかったですよね。
そんなちょっとしたシステムの補完をこのOCR機能がまかなえたなら、、いいと思いませんか?
もちろん動作確認は必要ですが、WinActor導入してるならEyeのOCR機能で読み取れるかもしれませんね。
WinActorEyeとは…
WinActorEyeとは、「ヒストグラム探索」および「OCR」という2つを備えたバージョン6.3.0からの新機能です。
「ヒストグラム探索」は簡単に説明すると、「画像マッチング」や「輪郭マッチング」の上位機能となるものです。
「OCRツール」はMicrosoft OCRのスクリーンショットOCR機能を用いてます。
さぁ、さっそく試してみよう!
下図の様にシナリオノードを作成頂いて、中の設定値を入れていきます!
①➁に関しては、動画でご確認下さい~^^

①Eyeマクロの作成方法!
少し手順が多めですので、動画で手順は見て下さい!!
1.OCR対象ウィンドウを開いておきます
2.Eye起動、マクロ記録の開始
3.OCRツール起動して、対象ウィンドウを選択
4.矩形から座標を抽出
5.マクロ保存
いかがでしょうか?
これでクリップボードにOCRで取り込んだ文字が記録されてます。
「4.矩形から座標を抽出」についてはOCRのみ利用する場合不要ですが、その後、ヒストグラム探索に利用する場合に必要となりますので工程として追加しておきました。
不要であればそのまま放置で問題ありません。
この次に、「WinActorノート」へペーストして欲しい文字列だけを抽出していく工程になります。
勿論、ペーストは「WinActorノート」でなくても、メモ帳でもExcelでもなんでもOK!!
また、PDFからでなくても、基幹システムの画面やWebサイトなどからでもOCR読取りできるかもしれませんね。
必要なのは毎回安定して読めているか、どうか。この当たりしっかり色んなデータを食べさせてあげて何度も確認してくださいね。
➁つぎにWinActorノートもマクロ作っちゃいましょう!
1.WinActorノート起動、記録スタート
2.データクリア
3.全ブロックの空白除去
4.記録ストップ、Jsonファイルで保存
5.シナリオ実行
6.OCR結果比較
さあ、完成です。OCRの精度はいかがでしたでしょうか?
皆様の目的が達成されます事、願っております(*^^*)
これがすべてではないですが、一つのアイディアとして、覚えていていただくと活用法も広がると思います!!
それでは、今日も素晴らしいRPAライフをお送りください!