今回はWinActorにおけるPDFからのデータ取得の可否について、またその取得方法について紹介します。
PDF上の文字には、カーソルで選択できるものと画像となっているものがあります。
1.PDFの文字が画像のもの
残念ながら画像となっているものは、
WinActorVer.6.3.0でWinActorEyeが登場し、Microsoft OCRが利用できますが、文字の抽出精度、文字の位置に関する矩形情報の精度などはMicrosoft OCRに依存するため、WinActorEyeとして動作保証はされていません。WinActorEye内でサンプルとして提供されています。

お手元にOCRソフトがあれば、そちらでテキストデータを抽出してからWinActorをご利用いただくことになります。
2.PDFの文字がカーソルで選択できるもの
一方、カーソルで選択できるものについては下記の方法等で対応が可能です。
PDFからテキスト情報を取得後、必要部分のみを抽出して利用します。
正しくデータが取得できないなど
PDFからテキストデータ取得を取得する
Step1 テキストデータを取得する
【方法1】ショートカットキー(Ctrl+C)でコピーしてクリップボードに取り込む
A.「エミュレーション」を利用する方法
≪手段①≫A座標からB座標まで(固定位置)ドラッグ、Ctrl+C(コピー)する
≪手段②≫Ctrl+A(全選択)⇒Ctrl+C(コピー)する
B.「画像マッチング」と「エミュレーション」を組み合わせて利用する方法
事前にマッチング用の画像を取得しておきます。
≪手段①≫画像の照合後、マウストリプルクリック⇒Ctrl+C(コピー)する
≪手段②≫画像の照合後、マウスドラッグ⇒Ctrl+C(コピー)する
【方法2】外部ツールを利用してテキストファイルに出力する(公式サンプルシナリオ利用)
Apache PDFBox(Javaライブラリ)を利用してテキストデータを取得する方法です。
「コマンド実行」でPDFBoxを実行し、テキストファイルを出力します。
※予めPCへJavaをインストールしていただく必要があります。
(Ver.5または6ご利用の方は、WinActor同梱のjava.exeをご利用いただくことも可能です。)

★コマンドプロンプト上で下記のようにコマンドを書き、PDFBoxを実行するとテキストファイルが出力されます。これをWinActorで実行します。
java -jar [PDFBoxパス] ExtractText [PDFファイルパス] [出力テキストファイルパス]※WinActorの公式サイトにサンプルシナリオがありますので、ご利用ください。
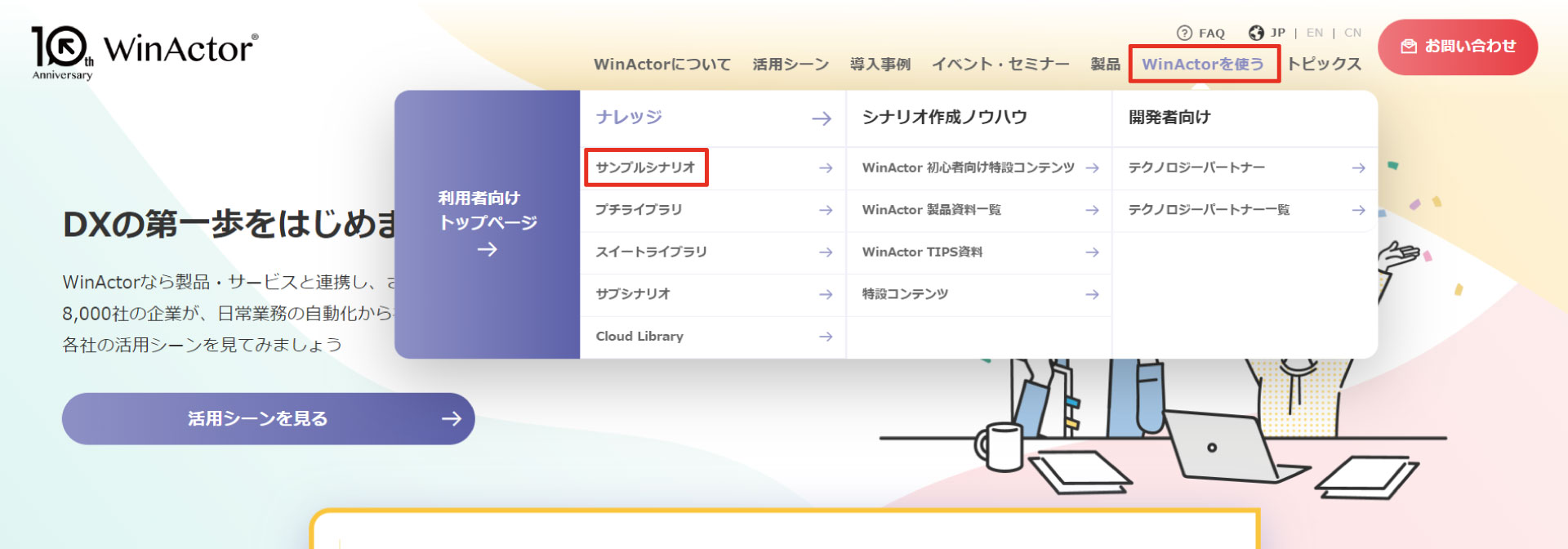
★サンプルシナリオの取得方法
「WinActorを使う」→「サンプルシナリオ」→「PDFから外部ツールで文字列情報を取得し、WinActorノートへ貼り付けを実行するサンプルシナリオ」を選択しダウンロードします。
Step2 取得したテキストデータから必要な部分のみを抽出する
【方法1】「WinActorノート」を利用し、必要部分を取得する(WinActorVer.6をご利用の方)
★「ライブラリ」→「25_WinActorノート」内のノードを利用します。
WinActorノートの使用法方法は、WinActorに付属の
・01_WinActorノート_操作マニュアル.pdf
・02_WinActorノート_テキスト処理シナリオ作成マニュアル.pdf
をご覧ください。

【方法2】取得したデータをExcelファイルに貼り付け、必要部分を取得する
主に「ライブラリ」➡「18_Excel関連」内のノードを利用します。

【方法3】テキストファイルを操作して、必要部分を取得する
主に
・「ライブラリ」➡「13_ファイル関連」➡「01_テキストファイル操作」
・「ライブラリ」➡「07_文字列操作」
を利用します。
【方法4】クリップボードのデータを変数に取り込み、必要部分を取得する
「ノード」➡「アクション」➡「クリップボード」を利用します。
今回はPDFファイルからテキストデータを抽出する操作方法について紹介しました。ぜひ使ってみてくださいね。
また次回をお楽しみに!
▼こちらもおすすめ